
tl;dr use hooks and simple heuristics to detect basic issues and steer Claude in the right direction if needed.
It started with a thought: “can digital signal processing concepts be applied to coding agent actions?” and if so: “can it do something useful?”
So I started a convo with Claude, who gladly responded with some ideas we could try out.
- Can we apply fast fourier transforms?
- Wrap agentics in an ADSR envelope?
- And then we mixed in Markov modelling - what signals can we detect by training a Markov model on the history?1
We ran it through a decision-critic which noted that FFT has nothing to do with what we wanted to accomplish, but noted that ADSR+Markov could be something to look into. In the end we concluded that a viable kernel for evaluation is parameterized effort profiles (derived from ADSR) + Markov transition analysis.
The next step we took was to implement a proof-of-concept model based on my local Claude Code conversation history (~1800 tool calls across 50+ sessions).
- Parsing CC conversation JSONL files into tool-call sequences
- First-order and second-order Markov transition models
- Run-length encoding to separate “which tool next” from “how long on one tool”
- classifying behavioral modes (Exploration, Execution, Search, Delegation)
- composite health score based on predictability (weight=0.40), entropy (weight=0.30) and run-length normality (weight=0.30)
A key finding that we observed in this stage was that a first-order model could predict the next step at 62% rate (e.g Bash->?, where ? could be Bash or Edit etc), whereas a second-order model could predict at 100% (i.e. Bash->Edit->?) - the high probability is likely due to small sample size. Nevertheless, something to work with.
So what would an interesting question be to try to answer with our model? We settled on the counterfactual approach: “What if we had intervened?”
To answer that question, we started by identifying intervention points: health dips, cycles and run-length outliers, then Markov-sampling alternative trajectories biased towards healthy behavioral modes then comparing actual vs simulated over a 12-step horizon. This led to our observing that decay spirals are real and that they are concentrated towards the end of big sessions (which we already knew) - approx 10% savings could be attained if we would have intervened.
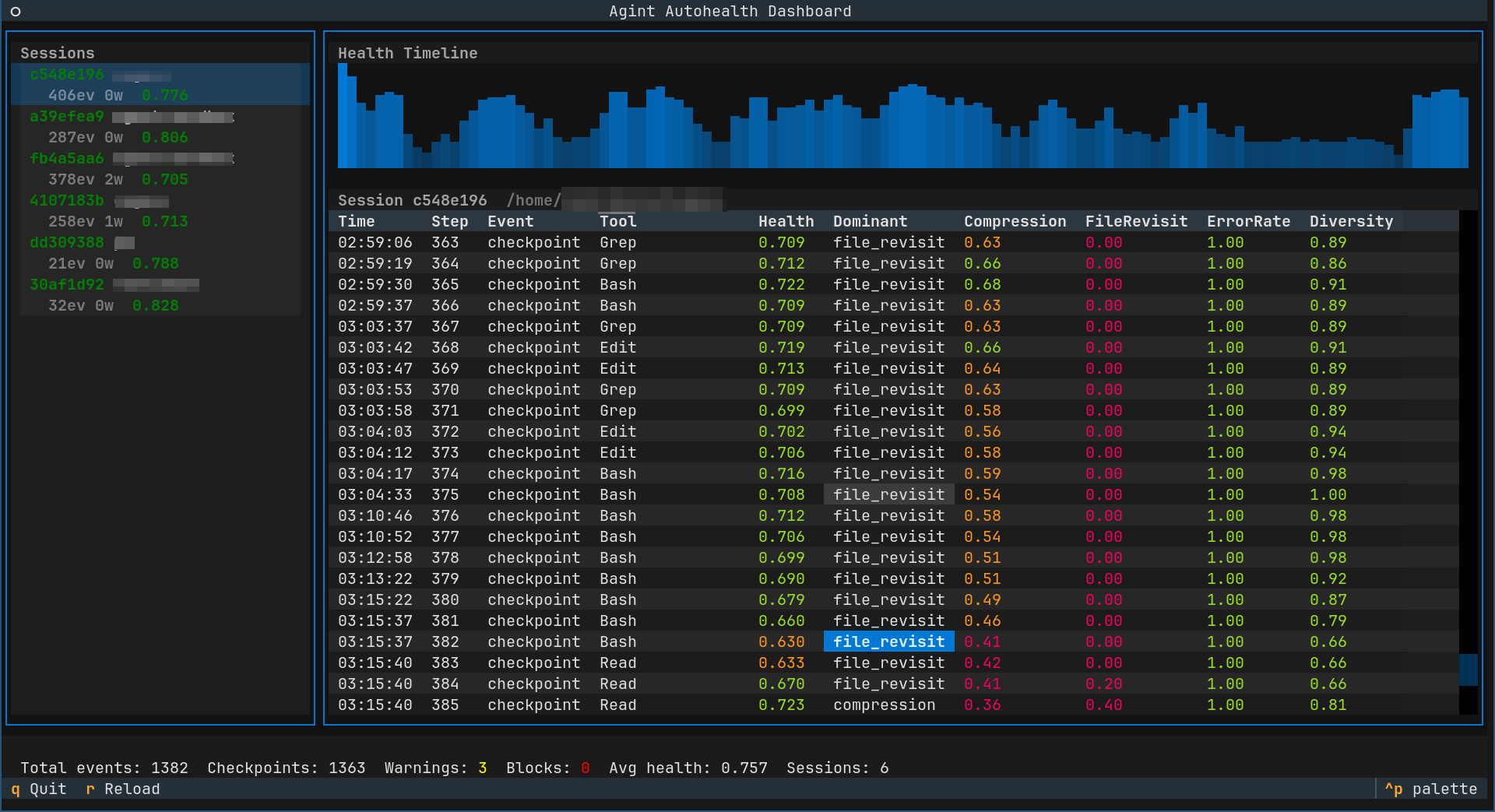
Okay, cool, we could save some tokens! But how to do it concretely? Well, in claude there are hooks2, among others, pre- and post tool use hooks. We decided on implementing a soft mechanism as a PostToolUse where if we detect a pathological trajectory, we would inject a message to the LLM that “hey, you’re spiraling; take a step back and think it through” or some variation. (We added also a PreToolUse hook, that could block its usage, but kept it disabled, so we don’t have any stats on its effectiveness). In addition to this, we added logging so that we could observe what the hook was actually doing. Following this, we could observe that our hook actually did identify pathological agent actions, and did its injection and everything. Cool! This also made us aware of the big chunk of false positives:
87 warnings across 358 events — a 24% warning rate.Something is wrong.
For one thing, Edit->Edit and Bash->Bash cycles were flagged as pathological, whereas they aren’t, and Edit(fileA)->Edit(fileB) isn’t even a cycle to begin with, but the model didn’t detect that because it just saw Edit->Edit.
We took a step back, and re-assessed our approach. The conclusion: the Markov-model was the weakest signal. Cycle detection is simple pattern matching, entropy is information theory and run-length is basic statistics. Maintaining and loading a Markov-model adds overhead (both cognitive and CPU/mem) for a mechanism that doesn’t drive decisions.
Instead, let’s build a purpose-built health scoring algorithm by direct measurement of the hook’s payload.
tool_inputgives us file paths and commands (not just tool names)tool_resultgives us error indicators
And so, we decided to compute a scalar health metric by composing the following:
- [0.20] zlib compression ratio as a single-number repetitiveness metric
- [0.20] file revisit frequency (same file visited many times in a row?)
- [0.20] bash error rate
- [0.15] diversity (entropy) of tool (is the same tool used many times in a row?)
- [0.15] blind retry (tool call with same args after error?)
- [0.10] null edit (edit of file resulted in no changes?)
What we’re saying here is that 20% of the score is whether “it compresses well or not” - which speaks to the repetition, 20% if the agent is hitting a wall trying to do something with one and the same file, 20% if the agent is having trouble with executing bash commands, 15% if the same tool is being used repetitively, 15% if a tool is called again with the same args after an error (only fools expect a different outcome - but then again, fools never had to deal with a flaky network) and lastly 10% failing to edit a file, when the intention is to edit a file.
This immediately fixes the false positives but still yields a useful metric!
So no longer is the autohealth monitor dependent on any trained Markov model (which is kept for after-the-fact forensics: replaying, analysing and diagnosing).
The end-result is a mechanism to automatically remedy pathological agentic spirals.
Learnings
- Start with a metaphor, but let data kill it - applying digital signal processing to agentics is a weird frame of mind, but it got us started.
- Simpler methods usually win - over-complicating things is seldom the way to victory
- False positives are worse than missed detections - wasting cognition is just bad
- richer inputs beat making your algos more sophisticated -
f(tool_name) -> outputwill never be able to match the richness off(tool_name, file_name, error) - signal taxonomy matters - classifying what you’re measuring and acting upon makes it easier to spot gaps and redundancies on your approach
Technical Stack
- Python 3.12, stdlib-only for hooks (json, zlib, math, collections)
- Claude Code hooks (PostToolUse, PreToolUse)
- Textual for TUI dashboard
- JSONL for trace logs
- No external dependencies in the hot path
Code
Footnotes
Footnotes
-
This relates to another silly idea: https://bjro.dev/posts/markymarkov ↩
-
When building the TUI, we made sure to check that sub-agents also called the hook - they do, and they inherit the session’s id, but has their own agent ids. ↩